CrowdStrike’s Crowning Kerfuffle
By Ravi Nayyar
I’ve been thinking about the recent CrowdStrike ‘ain’t a cyber security incident’-incident.
This saga that was labelled merely ‘a technical issue’ by the then-Commonwealth Minister for Home Affairs and Cyber Security.
Just an incident-non-incident, after all. (Never mind the A in the CIA triad being well and truly engaged here.)
The fortnight after the incident-non-incident was certainly a year, eh? Look at the photos of blue screens from around the world.
I’ll leave the introduction at that because, if you are reading my blog, you are most likely following the news in Infosec, especially when Mr Risky Business goes on holiday. Indeed, I’ve been writing about the software supply chain question since 2022.
The point is, this incident-non-incident is the case study which my thesis was designed for.
Look at the below graphic, inspired by my 2023 Cybercon preso.

3 regulatory circles pertaining to:
- the cyber resilience of critical infrastructure (‘CNI’) assets;
- software supply chain risk management (‘SCRM’) by CNI operators; and
- critical software risk to CNI assets (my thesis).
With this in mind, the CrowdStrike incident-non-incident has the ‘Thesis Trifecta’ for me:
- a critical software vendor messing up; which jeopardises
- the cyber resilience of the operators of critical infrastructure (‘CNI’) assets; and thus captures
- the incredible risks to national security from software supply chains.
To nut out the Trifecta, I’ve written three pieces: one on each Limb.
As the USG put it, ‘Sprawling supply chains, widening access to communications networks, and interdependent global infrastructures have led to an increasingly interconnected world’.
Let’s dive into that world with Article 1 on Limb 1, shall we?
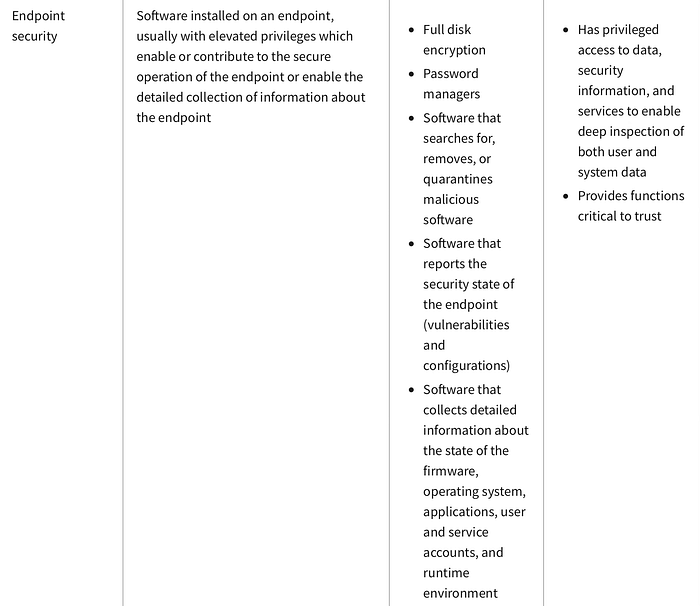
What’s Critical Software?
Well, this was an appalling stuff-up from a vendor of critical software (as defined by NIST).
But what is ‘critical software’?
Here is the definition of critical software from NIST (issued under Section 4(g) of Executive Order 14028 (‘EO14028’)):

CrowdStrike’s Falcon clearly fits the bill, not least because of the kernel-level access that it, like most EDRs, has to customer Windows boxes.
NIST recommended that the initial phase of the implementation of EO14028 focus on eleven categories of critical software, given that critical software ‘has security-critical functions or poses similar significant potential for harm if compromised’.
And among those eleven categories, you have EDR software.
To return to the definition of critical software, the criteria scream, ‘The stakes are high’, for:
- critical software vendors to get their ducks in a row from SDLC management and software SCRM perspectives;
- end-users, from safe deployment and software SCRM perspectives;
- the state, as appropriate, to assure that the latter two stakeholder categories — including the state’s regulated populations — get it right; and
- societies and economies, the software-dependent existence of which rests on all of the above stakeholders keeping themselves operationally resilient and overseeing that operational resilience.
The concept is hardly an esoteric ‘thing’ from some thought bubble someone had inside the White House. Indeed, the definition of critical software has been incorporated into memoranda (M-23–16, M-22–18, M-21–30) that have been issued — also under Section 4 of EO14028 — by the White House’s Office of Management and Budget with respect to how US federal agencies handle (critical) software and how they manage their software supply chains.
Hence, the significance of critical software is reflected in the regulatory obligations attracted by its security for USG agencies, including for how they procure software (we know procurement is a carrot for the Yanks, per Strategic Objective 3.5 under the National Cybersecurity Strategy, to encourage vendors to mend their ways).
To reiterate, we’re not talking about advisory stuff, rather actual rules that federal agencies have to comply with.
If critical software were irrelevant, why did EO14028 s 4(a) say, ‘The security and integrity of “critical software” … is a particular concern’.
Indeed, this is why my PhD research looks at how the regulation of the security and deployment of critical software fits into the regulation of the cyber resilience of CNI assets.
Because this stuff ought to attract super-special scrutiny — such as through formal legal regulation (not Smithy’s invisible hand) — from a state already sweating the national security consequences of a breach of CNI cyber resilience. And yes, of course, scrutiny from customers too, given what this stuff involves for their environments (as I will explain in more detail in Limb 2).
To speak generally, if you’re an attacker who finds a nice bug in/misconfiguration/other unsafe deployment of critical software in your target’s environment, ceteris paribus, ‘That’s gold, baby’ (as Jerry Seinfeld once said).
Again, look at the criteria for critical software.
A vendor not getting it right and/or the end-user not deploying it safely could, for all intents and purposes, be the same as rolling out the red carpet for baddies.
Because of technical realities, these products (like hypervisors) may not support EDR/logging and generally enable stealthy, persistent access to victim environments.
Logic errors thanks to these products, especially those with kernel access to the operating system, have the potential for causing major problems at the user’s end (ie the CrowdStrike incident-non-incident).
Look at why the Chinese, including Volt Typhoon, have shown edge devices like ESGs/VPNs/firewalls/SOHO routers as well as virtualisation software much love of late. Indeed, the Yanks disrupted a Chinese botnet of hundreds of US-based SOHO routers in January, having been used to conceal Chinese activity. The same day as when the disruption was announced, CISA and the FBI put out a Secure by Design Alert for SOHO router manufacturers, which referenced Volt Typhoon.
Note that I have popped other examples of baddies leveraging critical software in the Appendix.
But anyhoo, back to CrowdStrike and Limb 1 of the Thesis Trifecta: a critical software vendor messing up.
And gee whiz, did they stuff up.
What Happened: The Quick and Dirty Version
From CrowdStrike’s Preliminary Post Incident Review (‘Preliminary PIR’, dated 24 July) for the incident:
On Friday, July 19, 2024 at 04:09 UTC, as part of regular operations, CrowdStrike released a content configuration update for the Windows sensor to gather telemetry on possible novel threat techniques.
The problematic Rapid Response Content configuration update [(‘RRC update’)] resulted in a Windows system crash.
Systems in scope include Windows hosts running sensor version 7.11 and above that were online between Friday, July 19, 2024 04:09 UTC and Friday, July 19, 2024 05:27 UTC and received the update. Mac and Linux hosts were not impacted.
(The company said on 31 July UTC that around 99% of Windows boxes are back online.)
Basically, the updated baddy-detection instructions (the RRC update) sent by CrowdStrike to its sensors triggered a logic error which bricked not just the sensors but also the Windows boxes running them, given that the sensors had kernel-level access to them.
The issue which this bad update triggered was so bad on the Windows machine that it would, on rebooting, get Falcon rolling again, repeating the crash.
(The Pragmatic Engineer, The Register and Risky Biz News have great explanations of what happened.)
To make matters worse, the process for customers to recover their Windows machines was quite fiddly (eg if boxes had BitLocker switched on), especially since each machine had to be physically accessed. (To their credit, Microsoft put out a tool to make the recovery process easier.)
This created live case studies for how ordinary cyber resilience work is not what movies/stock photos used by media outlets portray it to be.
Indeed, this incident revealed just how many organisations don’t have an inventory of their BitLocker keys.
As I observed, customers should thank CrowdStrike for forcing them to do an asset inventory. Machine by machine.
But this update was put out by CrowdStrike, a dozens-of-billions-of-dollars cybersecurity vendor, not a malicious actor who wanted to cause chaos, right?
We need to understand the finer details here, including the quality of testing of these updates.
If any.
What Happened: The Nitty Gritty
For this, I’ll be especially leaning on CrowdStrike’s Preliminary PIR and technical root cause analysis (dated 6 August).
Definitions
Let’s first define Template Types v Instances.
A Template Type is sent as part of Sensor Content updates to modify Falcon sensor capability by adding telemetry and detection. It supplies the Content Interpreter on the sensor with what behaviour the sensor should be looking out for to match with a Template Instance.
A Template Instance is Rapid Response Content and an ‘instantiation’ of a Template Type while preserving the sensor’s code.
Each Template Instance ‘maps to specific behaviors for the sensor to observe, detect or prevent’ — it provides ‘behavioral heuristics’ for the sensor to act on. It is ‘used to gather telemetry, identify indicators of adversary behavior, and augment novel detections and preventions on the sensor’.
Template Instances are sent by Channel Files (RRC updates). Each Channel File carrying (a) Template Instance(s) is matched with a particular Template Type.
Having made clear who’s who in the zoo, let’s get into the nitty gritty of 19 July 2024.
This Case
Actually, let’s rewind a few months.
In February 2024, CrowdStrike created a Template Type for spotting the exploitation of Windows interprocess communication processes (the ‘IPC Template Type’).
They successfully stress-tested it in their staging environment in March.
As a matter of course, Channel File 291 was designated as the file carrying IPC Template Instances to operationalise the IPC Template Type.
Now, the definitions file for the IPC Template Type told the Content Interpreter on a sensor to look out for 21 input sources— this is ‘the activity data and graph context’ — to match against in IPC Template Instances.
The Channel File 291 of 19 July deployed two new IPC Template Instances that together, for the first time ever, required the sensor to inspect the 21st input field.
CrowdStrike’s Content Validator had previously waved these new IPC Template Instances through testing because it was expecting that the Content Interpreter would be supplied values for 21 input sources, as specified by the IPC Template Type.
Except the sensor code (separate to the definitions file) for the IPC Template Type told the Content Interpreter to expect data on 20 input sources.
And, obviously, 21 > 20.
Having expected 20 values, the Content Interpreter in each sensor got upset when it tried to inspect a value for the 21st input field as required by the 19 July version of Channel File 291.
More specifically, it triggered ‘an out-of-bounds memory read’ and thus a BSOD on the Windows box.
Tangentially, Brian in Pittsburgh provides a good explanation of why CrowdStrike’s driver, which actually runs the Falcon sensor, being written in a memory-unsafe language was a recipe for disaster.
(‘more input than it knew how to handle’ refers to the 21 ≠ 20 mismatch.)
But what about testing?
No, Testing Was Not up to Scratch
First things first, according to the Preliminary PIR, prior CrowdStrike procedures meant that new Template Types went through layers of testing:
The sensor release process begins with automated testing, both prior to and after merging into our code base. This includes unit testing, integration testing, performance testing and stress testing. This culminates in a staged sensor rollout process that starts with dogfooding internally at CrowdStrike, followed by early adopters. It is then made generally available to customers.
Pretty darn comprehensive, right?
But Template Instances did not go through the same level of testing.
Now, regarding the incident-non-incident, note this from the Preliminary PIR:
Based on the testing performed before the initial deployment of the Template Type (on March 05, 2024), trust in the checks performed in the Content Validator, and previous successful IPC Template Instance deployments, these instances were deployed into production.
And this from the root cause analysis:
This mismatch was not detected during development of the IPC Template Type. The test cases and Rapid Response Content [IPC Template Instances] used to test the IPC Template Type did not trigger a fault during feature development or during testing of the sensor 7.11 release.
Evidently, CrowdStrike didn’t sufficiently check whether the new Template Instances were problematic.
Not only was their Content Validator not up to scratch (giving a false negative) but they literally ran with ‘She’ll be right, mate’ because they trusted the validator and prior Template Instances not throwing up issues.
If the vendor had reasonable testing arrangements in place for IPC Template Instances, it is very hard to argue that this issue would not have been caught by CrowdStrike.
Because a BSOD isn’t exactly a subtle result of a logic error which your thing induces on a Windows box, especially via the kernel.
As pointed out by Kevin Beaumont, while the Preliminary PIR talks up a storm about testing, it appears this was a case of ‘Zero real testing in reality’.
Oh, Come on
CrowdStrike are a critical software vendor but they didn’t test their own stuff properly before deploying it to millions of customer kernels.
Justin Cappos presciently spoke for all of us on 19 July itself:
It strains credibility that any organization, much less a security company, would fail to have robust software supply chain validation mechanisms in place. The fact that software could be released without testing demonstrates a level of negligence, I’m shocked to see from a major security company.
Mr Risky Business had similarly strident views on 24 July (emphasis added):
… when you look at this, given that this was a 100% reliable ‘blue screen of death’ against every machine that it [the updated config file] touched, the only conclusion you can draw is: A) it doesn’t matter what the problem is; because B) they obviously didn’t do any testing … you can talk to people who say, “Well, testing is hard and whatever”. Not in this case: 100% reliable instant blue screen of death. And you just think, “What the ****?”
… CrowdStrike absolutely made a terrible mistake and it’s baffling … there’s no version of this in which this looks at all like, “Oh, okay, I can see how that happened”. Like, there’s no version of this where it looks reasonable. Just forget it.
As made clear by Patrick, the sheer uniformity of the BSODs on Windows boxes makes the ‘Oh, complex!’ defence simply untenable.

In a 30 July discussion with Patrick and Chris Krebs, SentinelOne’s Alex Stamos pointed out on 30 July that his company have much more comprehensive testing for all updates (ie they don’t pick and choose what types of content gets tested more than others). In that discussion, Patrick summed up CrowdStrike when he said that they dogfood their updates ‘but they’re a Mac shop’.
To wit, look at Florian Roth’s comment on the external technical root cause analysis: ‘… a single $400 canary machine could have prevented this disaster’. (I’ve put his full post below.)
It’s as if CrowdStrike didn’t put in place controls recognising the nature of its actual customer base.
Now, in vendor liability questions, the notion of a ‘duty of care’ (akin to that in tort for any actor) has come up a regulatory lodestar. The USA’s 2023 National Cybersecurity Strategy declares that software vendors ‘must … be held liable when they fail to live up to the duty of care they owe consumers, businesses, or critical infrastructure providers’.
I’m not sure how the above would mean that CrowdStrike didn’t fail to take reasonable steps to protect Falcon customers who were running Windows.
This is absolutely bonkers.
This is unforgivable, no matter what people say about how ‘we must not assign blame, we need to learn from this and not act in anger, we need to smoke the peace-pipe, stand in solidarity with the hard-working people at [a billion-dollar listed company], yada, yada, yada’.
No matter what people say about how ‘these updated baddy-detection instructions need to be pushed out as quickly as possible because security!’, which Florian Roth satirised really well.
Indeed, the CrowdStrike approach to RRC update testing has whiffs of the attitude behind shipping code to production on a ‘YOLO’ basis.
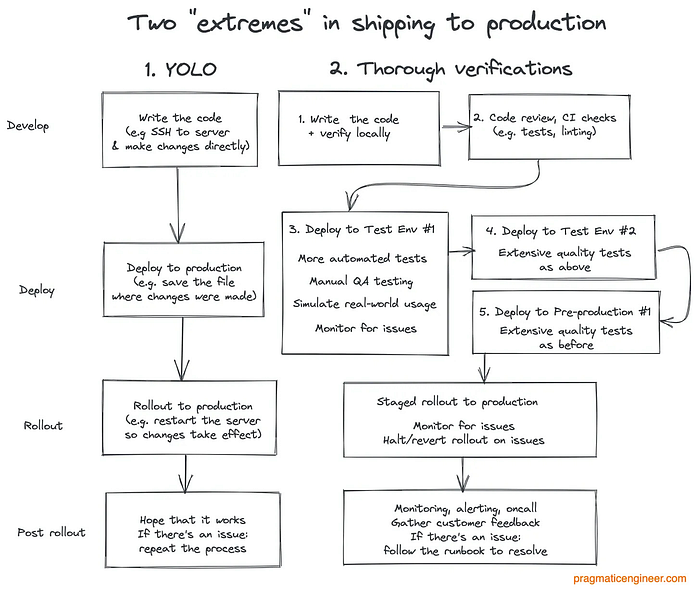
Delta Air Lines, CrowdStrike’s incensed customer, certainly agrees, given the terse nature of its reply (though its lawyers) to CrowdStrike’s counsel:
… CrowdStrike’s Preliminary Post Incident Review (“PIR”) confirms that CrowdStrike engaged in grossly negligent, indeed willful, misconduct with respect to the Faulty Update.
CrowdStrike’s Root Cause Analysis (“RCA”) of the Faulty Update … admits that had it maintained basic software development, testing, and validation procedures, the July 19 disaster from the Faulty Update would not have occurred.
Tangential fun fact: AT&T’s nationwide outage in February 2024 was thanks to, eg, its failure to adequately test, and oversee the testing of, a network change, as found by the Federal Communications Commission (emphasis added):
… several factors, including a configuration error, a lack of adherence to AT&T Mobility’s internal procedures, a lack of peer review, a failure to adequately test after installation, inadequate laboratory testing, insufficient safeguards and controls to ensure approval of changes affecting the core network, a lack of controls to mitigate the effects of the outage once it began, and a variety of system issues that prolonged the outage once the configuration error had been remedied.
Promising to Do Better
One can argue that CrowdStrike have implicitly admitted to following a YOLO approach with respect to writing and shipping Template Instances as part of RRC updates.
After all, look at what they’ve promised on testing. (See also the detailed external technical root cause analysis which CrowdStrike released a few days since this article was published.)

Seems rather comprehensive, doesn’t it?
They’ve even pledged to improve the functioning of their Content Validator and Content Interpreter. Gee, I wonder why.
And when it comes to willy nilly tweaking how customer sensors operate by sending them new threat detection, etc instructions, well, CrowdStrike have realised that the status quo is far from, well, safe.

When combined with the pledge to test RRC updates more robustly, this is welcome.
After all, CrowdStrike showed the world what a single point of failure looks like. It showed a self-portrait, to be precise.
It’s just basic customer protection by critical software vendors to not modify the behaviour of all customer endpoints/environments in one fell swoop.
Doing a YOLO as a vendor with kernel-level access to other people’s Windows boxes is hardly ideal.
Hence, it’s good that, as they already do with Sensor Control updates, CrowdStrike have said that they’re going to do things in a staggered fashion. This is enhanced by the greater agency afforded to customers regarding what, when and where RRC updates are deployed to their sensors, as well as the vendor getting feedback from them.
Transparency and giving more control to customers always helps.
Even if doing things like better testing, more cautious deployment of stuff to their boxes and giving them more of a say in how the product runs are basic as heck.
(Also, good to see that CrowdStrike has commissioned two independent third party software security vendors ‘to conduct further review of the Falcon sensor code for both security and quality assurance’, in addition to CrowdStrike’s ‘independent review of the end-to-end quality process from development through deployment’.)
Culture
Such promises to do better in required areas are excellent because what has been the case ‘Under the Wing’ has been, checks notes, bad.
Questions remain about CrowdStrike’s approach to product security and customer welfare. Yes, it’s all well and good to look at things with the benefit of hindsight. Except the failures in control design are so basic that one hopes the snafu can be explained through Hanlon’s Razor alone.
And it is because CrowdStrike’s failures are so basic that one is reminded of the company which CrowdStrike and its CEO have thrown snarky remarks at and still have a page explaining why they’re a better shout than that company.
After all, doesn’t the recent incident-non-incident — especially CrowdStrike’s own admissions and promises regarding testing — reflect that CrowdStrike’s security culture is ‘inadequate’, as the Cyber Safety Review Board (‘CSRB’) described Microsoft’s?
Doesn’t the following CSRB commentary on Microsoft apply to CrowdStrike as well:
… in light of the company’s centrality in the technology ecosystem and the level of trust customers place in the company to protect their data and operations.
This position brings with it utmost and global responsibilities. It requires a security-focused corporate culture of accountability …
… point to a corporate culture … that deprioritized both enterprise security investments and rigorous risk management. These decisions resulted in significant costs and harm for Microsoft customers around the world.
It’s that juxtaposition of the criticality of the software/services provided by the vendor to economic activity at large with the vendor’s below-par security/risk culture. Can’t this capture the situation at CrowdStrike, especially given the sheer number of businesses and government agencies around the world hit by this incident-non-incident?
CrowdStrike are well aware of their importance to the national security of a number of (advanced) economies (just look at their website and marketing), given the nature of their customer base. And yet, this happened.
To ask a facile rhetorical question (to further spark debate), shouldn’t CrowdStrike have invested the same amount of attention in ensuring updates pushed to customer instances won’t trigger BSODs as they do in naming and commissioning cartoons + merchandise for threat actors?
And again, the incident-non-incident was not an attack, but an unforced error.
Making the saga even more alarming, given the fallout for societies and economies.
Something which David Swan, Technology Editor for the Sydney Morning Herald, reminded us about in relation to the great Optus outage of 2023.
That outage was because of Optus’s own boo-boo — its retention of factory settings on Provider Edge routers that didn’t like new routing instructions from the parent company’s peering router and thus took the consumer IP network (and dependent services) down with them.
A major national telco. A global EDR vendor. Both falling down of their own accord. With terrible negative externalities.
Heads Must Roll
And this is why heads must roll at said vendor (as they should have at said telco, which saw the CEO and networks chief resign).
How should or can any one of the CrowdStrike fat cats’ gigs be safe?
Just look at the share price since the incident-non-incident.
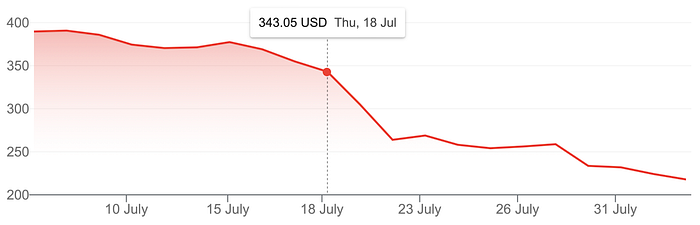
Folks, we can have the debate about what corporate law actually is (shareholder- versus stakeholder-centric), but we’ll do that another day (and my PhD research deals with this point too, so stay tuned for that).
In any case, I’m not so sure how the company’s share price, (potentially) its client book and definitely its reputation taking a hit like that fits any definition of corporate governance.
The Law
Anyhoo, given that CrowdStrike is a US company, let’s have a quick look at the fiduciary duties of care and loyalty (and subsidiary duties) of directors under US law. To summarise the hyperlinked resources, directors have to, essentially:
- exercise the degree of care which an ‘ordinarily prudent person’ would have done in a similar position and circumstances;
- act in good faith in the best interests of the company; and
- provide adequate oversight of management’s running of the company, including by ensuring the implementation and maintenance of reasonable information and reporting systems so the Board and senior management are informed on how the company is performing in a timely fashion.
To grossly oversimplify, the caselaw (such as the 1996 Caremark litigation, Stone v Ritter and the 2017 Wells Fargo shareholder derivative action, analysed in the hyperlinked materials) establishes a high bar for directors to be held liable in private civil actions (by shareholders/through derivative suits) for breaching these duties. There’s gotta be stuff like:
- ‘intentionally’ acting with an ulterior motive or ‘demonstrating a conscious disregard for [their] duties’;
- knowingly ‘utterly fail[ing] … to implement any reporting or information system or controls’ or ‘consciously fail[ing] … to monitor or oversee its operations’; or
- ‘consciously regard[ing]’ the fact that failures have occurred, including after being informed of such issues.
Of course, if they’re sued through such actions, directors can invoke the business judgment rule (see the 2005 Disney shareholder derivative action; US law is kinda sorta like our Corporations Act 2001 (Cth) s 180(2) on this front). In such a scenario, the court will presume their decision was legal ‘unless it cannot be attributed to any rational business purpose’, or it featured ‘unintelligent or unadvised judgment[s]’.
Note that the SEC also has civil jurisdiction (the DOJ, criminal) with respect to US securities laws and regulations.
Which Means?
I’ll leave detailed analysis, including on the question of liability, to US legal experts and academics because I’m more familiar with Australian corporate law and this article is not a legal analysis.
By my back-of-the-envelope application of the above legal tests, the CrowdStrike Board certainly has serious questions to answer, even if a private or regulatory action against them may not be likely to succeed thanks to evidential requirements for the plaintiffs. Shareholders certainly think they have a case: their class action names the CEO and CFO as defendants in addition to the company.
Note that the legal calculus for corporate governance directly drives the ethical one or even that in the court of public/customer opinion for the Board.
Even if media coverage dampened after a few days to a week — especially when Biden dropped out of the 2024 race — one could argue that at least CrowdStrike’s major customers would be asking serious questions.
Certainly, Delta Air Lines and its CEO has been jawboning like an absolute champion, though one wonders if Delta merely seeks to win the narrative battle and extract a hefty amount of compensation — without going to/out of court — from a company whose reputation has taken a most frightful battering.
CrowdStrike has certainly jawboned back through its lawyers.
Having read Delta’s reply (though counsel, dated 8 August) to CrowdStrike’s jawboning, I’m wondering if CrowdStrike has thought their PR strategy through.
While there are doubts about Delta’s chances of extracting damages from CrowdStrike at trial (but see also this view), its 8 August letter alone would send chills down the spine of a partnerships/customer relations manager at any supplier.
In addition to Delta’s arguing that CrowdStrike has confirmed it engaged in tortious conduct, here are some juicy extracts (emphasis added):
We were even more surprised and disappointed by CrowdStrike’s decision to try a “blame the victim” defense.
CrowdStrike’s offers of assistance during the first 65 hours of the outage simply referred Delta to CrowdStrike’s publicly available remediation website …
CrowdStrike CEO George Kurtz’ single offer of support to Ed Bastian on the evening of Monday, July 22, was unhelpful and untimely.
Delta’s reliance on CrowdStrike and Microsoft actually exacerbated its experience in the CrowdStrike-caused disaster.
Rather than continuing to try to evade responsibility, I would hope that CrowdStrike would immediately share everything it knows. It will all come out in litigation anyway.
On top of everything CrowdStrike has put itself through since 19 July, the reputational damage from that one letter, on top of what I’ve been hearing from folks in industry about CrowdStrike’s increasingly uncertain client book, is most likely to be significant.
Delta’s counsel have even provided a label for the event: ‘The CrowdStrike disaster’.
In light of all the above, customers, governments and shareholders must ask the CrowdStrike Board if it ever sought:
- a briefing on how their company updates the functionality of customer sensors and who writes these updates (ie kernel engineers versus threat analysts?);
- an independent opinion on the safety of these update mechanisms (for customers especially), including the quality of testing of updates;
- an explanation of why RRC updates were not previously tested with the same rigour as Sensor Content updates when both species of updates are affecting/flung into the kernel;
- an explanation of why RRC updates were simply delivered to customer sensors en masse, as opposed to in a staggered fashion;
- to create robust feedback loops with senior management on updates to CrowdStrike’s core product lines, especially given how a bad CrowdStrike update bricked a lot of Linux boxes in April; and
- to war-game the reputational, regulatory, operational and financial impacts of any updates to their core product lines.
If the answer to any of these questions is ‘No’, the Board needs to take a good, hard look at itself.
For these questions directly touch on the ability of the company to operate in a manner which merely does not harm its own reputation, customer book and thus its finances (see the crash in the stock price).
These questions not only touch on the directors’ fiduciary duty of care but also on that of loyalty, given that said questions go directly to whether they are discharging their oversight role. Namely, whether they are preventing management from driving the company’s share price and reputation into the ground.
After all, which ‘ordinarily prudent’ person sitting on a Board of a global EDR vendor somehow doesn’t inquire about the vendor’s steps to solidly mitigate the risk of their brand entering the zeitgeist, SolarWinds-style, due to their failing to have robust controls?
In the present case, steps with respect to deploying those updates to customer instances only when sure that respective updates will not cause a rude shock for customers?
After all, CrowdStrike is paid to minimise the risk of stuff which throws customer operations into disarray.
Not inflict a de facto ransomware attack on customers.
Were CrowdStrike directors acting in good faith in the best interests of the company when they allowed the company to do something so unmistakably stupid?
This incident-non-incident is perhaps arguable as symptomatic of serious corporate governance failures at the vendor.
How else does this happen?
In fact, if one looks at the experience of CrowdStrike, one can’t but help to be reminded of what happens in militaries when units experience similarly serious failures or lack of effective governance.
Like (widespread) failures to perform adequate risk assessments and understand basic operational practice, a disregard for safety procedures, leadership vacua, ineffective culture and discipline. Just have a read of the USAF’s Aircraft AIB report on the crash-landing of a B-1B bomber at Ellsworth AFB in January: wowee, were the 28th Operations Group found wanting in the oversight department (my summary).
To return to the immediate incident-non-incident, if we look at the fallout, there have been whispers about whether CrowdStrike can even retain (let alone grow) its customer book and how long the vendor’s directors even retain their positions. Its shareholders are suing CrowdStrike because it (including through the CEO) was allegedly fibbing about its software being safe and tested prior to the saga. And, to reiterate, that suit names the CEO and CFO as defendants in addition to the company.
Folks, any corporation’s Board, as its stewards appointed by the shareholders in general meeting, is its break-glass check.
You can argue that shareholders in general meeting are that check but I disagree. It’s too late by that stage anyway whether we’re discussing an attack or a non-malicious outage, given how quickly circumstances change (for and due to any stakeholder) in the cyber context.
Whether a company is mitigating the risk of an attack or self-inflicted stupidity, the buck stops with the Board — the company acts through them.
If they can’t do their jobs, especially oversight of management and acting in a reasonably informed fashion to promote CrowdStrike’s interests, they should step aside.
Don’t Distract from the Governance Vacuum
It is imperative that we not distract from the critical fact here: this incident-non-incident has its roots in below-par corporate governance, perhaps even a governance vacuum, at CrowdStrike.
While Infosec folk have kept stressing this since the beginning (even before the vendor came out and said they didn’t test the RRC update properly), the media has failed to adequately prosecute the stupidity of this incident-non-incident, having initially blamed it on Microsoft and then shifted the news cycle to the US election.
The non-cyber commentariat generally has also been found wanting.
Talk of the need to have multiple vendors is futile without inquiring if these vendors have suboptimal corporate governance like CrowdStrike. It’s little point having multiple baskets to place our cyber resilience equities in if each basket is flimsy.
Talk of how CrowdStrike ought to be recognised for the speed with which it identified the issue and came up with a fix, for its ‘transparency’ and for the CEO’s swift ‘apology’ is necessarily incomplete without interrogating how the Board allowed CrowdStrike to bring this saga upon its brand and its customers (including those in CNI and the public sector) in the first place.
Oh, and CrowdStrike wasn’t acting swiftly to ‘fix this’ because it’s a charity: it was desperately seeking to preserve its business, especially with the public sector, given the aftermath (more in Limb 2).
Also, on that ‘transparency’, ‘apology’ and comms, well, that’s debatable. Juan Andrés Guerrero-Saade of SentinelOne regarded the firm’s Preliminary PIR as so carefully-worded that he had a ‘hard time parsing it’. Patrick Gray and Adam Boileau were in agreement that the company’s PR has ‘been absolutely appalling’. Rob Graham had far less charitable words for the attempted apology/ad from the CrowdStrike CSO.
The ‘But they’re not Chinese’ argument (which has also been thrown up) misses the point entirely. It is, quite frankly, immaterial. Once customers pay CrowdStrike for EDR after doing relevant foreign influence screening of vendors, they expect to be protected regardless.
The ‘But they’re not a Chinese vendor’ line doesn’t help their recovery and diverts attention from the overworked IT workers trying to clean the mess left by CrowdStrike at their organisations over a good couple of days (and during subsequent ‘teething issues across the economy’, as put by the then-Commonwealth Minister for Home Affairs).
Comparing CrowdStrike’s response and ‘transparency’ to China’s attempts to do espionage/disruptive hacking via software supply chains à la xz-utils/‘national champion’ vendors is unsound.
If anything, it makes CrowdStrike look worse than it already does, given that it committed the world’s largest friendly ransomware attack actually from its exalted position as a ‘trusted vendor’, indeed one of the pre-eminent trusted cyber resilience vendors.
It has also been argued that the incident-non-incident is a reminder of the need for greater investment in sovereign cyber resilience capability (as per what countries like mine and the USA have committed to do under national cyber security strategies).
The reality is, however, that all of your investment (promotion), your workforce development initiatives and work fostering domestic industry clusters will be ultimately for nothing if your sovereign vendors don’t have good enough corporate governance to prevent (yes, prevent) such a basic stuff-up like CrowdStrike’s.
And this is before we get to how complex SDLC management for any software product is.
Be it CrowdStrike, SolarWinds or Microsoft, everything is downstream of (a lack of) corporate governance. Especially impacts on national security.
If you ignore the corporate governance question here — the central animating question — in your commentary, then, like the CrowdStrike Board, you have serious questions to answer.
Speaking of corporate governance, the CrowdStrike CEO was the McAfee CTO in 2010 when the latter firm also put out an infamous update which bricked millions of machines.
Well, it’s not as if that dented his/his Board’s careers, so I guess no directorial/senior executive heads will roll, as per usual in this business.

(Separately, I note that the commanding officer of the USAF’s 28th Operations Group was sacked ‘due to a loss of trust and confidence in his ability to command, based on the findings of [the aforementioned AIB report on the B-1B crash]’.)
By the way, I heard that CrowdStrike sponsored the Victorian Cyber Security Showcase (held on 23 July 2024), but they were so embarrassed that they didn’t turn up (including to a lunch they were meant to co-host). And (relevant bits on) event banners were taped over.
Making the below quite amusing.
Privilege of EDR Products
Given that Falcon (like most EDR products) requires kernel access to function on Windows boxes, a key debate surrounding this incident-non-incident is the future of the kernel-access model itself for third party software. I’m not at all technically knowledgeable in this highly specialised department, so I will leave the field to those who actually know what they’re talking about and flag some of their key talking points:
- The stability-security trade-off for users of EDR products operating in the kernel;
- EDR products being far from perfect in their operation, calling into question whether they deserve kernel access;
- Whether EDR products actually require kernel access to do their jobs (on top of their having a hard time due to anti-tampering controls in operating systems and baddies trying to disable/bypass them);
- The antitrust v security question raised by Microsoft/EU in terms of giving kernel access to third party EDR products;
- The merits (or not) of the Apple approach whereby no third party has direct kernel access, rather the operating system vendor creates an API to replicate that access but third party stuff still runs only in user mode;
While we wait for this debate to be resolved by vendors, experts and regulators, the question remains of what happens in the immediate future.
First things first, EDR vendors (or cyber resilience vendors more generally) enjoy the ‘confidence’ of customers and indeed non-specialist policymakers.
To the contrary of the ideal scenario.
As Kevin Beaumont put it in his write-up:
We should have zero trust in cybersecurity vendors’, given that ‘the cybersecurity industry has failed upwards to the point of having administrator access to almost every PC on earth, out of apparent necessity.
Policymakers and regulators have failed to check this (or at least receive sufficiently independent advice on this front) while requiring organisations to have these tools to meet operational resilience regs, which Kevin stressed.
The extraordinary privileges at which these products operate (as critical software products) create extraordinary risks for organisations running them: what happens if the (SaaS) vendors get pwned/bugs in these products get exploited by baddies? This problem is especially real if security products enforce zero trust methodologies, given that they are the source of truth when it comes to identity within a customer environment, as pointed out by Kelly Shortridge.
Like with critical software vendors generally, the problem is a dearth of direct regulatory oversight.
Where are the transparency requirements for vendors so prospective customers can review their SDLCs, source code as well as their own cyber governance?
Where are the industry standards and metrics — bar marketing gimmicks and snark from vendors — to judge the products against?

Indeed, when critical software vendors like CrowdStrike are referred to by the commentariat as ‘trusted vendors’ (because they’re not Chinese and came clean so quickly about their bricking millions of Windows computers worldwide), there is a larger question on the degree to which that trust is even informed because of vendor marketing or the customer lacking the bargaining power/the awareness to ask the vendor to be transparent about their controls or submit to independent audits as part of the procurement process.
Folks, recall that vendors are not special, entitled to protected species status because ‘Ooo, fancy software’: they’re companies selling a product/service like anyone else. It’s amusing to see folks go after the big banks as part of some crusade against capitalism, but then ignore the sheer volume of financial (not broader operational resilience) regulations — especially after the GFC — that are designed to keep said banks and the broader financial system healthy.
Critical software vendors don’t have such direct regulation. They may be regulated indirectly because they’re part of the supply chains of CNI asset operators (eg as ‘Bank Service Providers’ under the Bank Service Company Act, codified at 12 USC §§ 1861–7) or they are ‘incentivised’ to do better through government (procurement) regs pertaining to software security (eg M-23–16, M-22–18, M-21–30, flagged above; I’ve written about the benefits of the carrot-based approach).
But they do not face mandatory standards for the quality and reliability of their wares (perhaps beyond consumer law) or mandatory auditing requirements of their own like normal regulated sectors. (I note that the EU is amending its product liability directive to include software and enacting a specific regulation for the security of software generally.)
As Kevin put it:
I think the cybersecurity industry is still very immature compared to its journey to come, and we’re just a bunch of dorks with far too much power currently.
It could be argued that the CrowdStrike incident-non-incident, given the externalities, provides the trigger for shifting the conversation on creating bespoke regulation of (critical) software vendors. Or at least laying the foundations for consensus on the need for that reform because what happened is such a significant case study for the consequences of vendors being allowed to run their own show.
Like how the investment banks gave us the GFC because the Yanks, eg, de-regulated derivatives.
Conclusion
The incident-non-incident is negative externalities writ large.
Including for CrowdStrike’s own reputation, as flagged above.
And we’ll be dealing more with the negative externalities at play when we talk about Limb 2 — the cyber resilience of the operators of CNI assets being jeopardised by a critical software vendor stuffing up.
Which shall be dealt with by Article 2 in this series.
Appendix — Critical Software-Enabled Attacks against CNI Assets
Here’s a slide from my 2023 Cybercon preso.

In there, you’ve got:
- Stuxnet (likely 2005–2010) — Iranian defence industrial base (we know what those centrifuges were for); bugs in OT software;
- BlackEnergy (2015) — Ukrainian electricity utilities; lack of MFA on operators’ remote access software + using local SCADA deployment to open circuit breakers;
- WannaCry (2017) — UK and/or European healthcare, telecommunications and railway services; Windows bugs.
- AcidRain (2022) — satcom/Internet for the Ukrainian military and parts of Europe (eg primary comms for French emergency services + remote monitoring and control for 5,800 wind turbines); misconfigured VPN.
Also note attacks like:
- Colonial Pipeline (2021) — US liquid fuel; VPN being sans MFA;
- allegedly, Medibank (2022) — Australian insurance; VPN being sans MFA;
- DP World (2023) — Australian stevedoring (with serious flow-on effects for Australian logistics); unpatched Citrix (#CitrixBleed); and
- Several MSPs (like Visma EssCom) and hundreds of Coop supermarkets in Sweden (2021) — data storage and processing, Swedish food and grocery; malicious Kaseya update.
The critical software products targeted in these examples reflect the growing cybercriminal preference, as identified in the ENISA Threat Landscape 2023, for remote monitoring and management tools in order to (easily) establish and maintain persistent access to victim environments.
After all, these are ‘trusted products from trusted vendors’, so customer environments would not be treating traffic coming through/from these boxes/their update channels as inherently suspicious.
#CriticalSoftwareMatters

