CrowdStrike’s Complicating Critical Infrastructure Cyber Resilience
By Ravi Nayyar
Welcome to Article 2 in this series on the CrowdStrike incident-non-incident.
(Here’s Article 1, by the way.)
As I wrote in that one, the way I label the CrowdStrike saga is inspired by the choice of wording from the then-Commonwealth Minister for Home Affairs.
As I also flagged in that piece, this incident-non-incident, the great CrowdStrike Falcon Fiasco, is the case study which my thesis was designed for.
Look at the below graphic, inspired by my 2023 Cybercon preso.

3 regulatory circles pertaining to:
- the cyber resilience of critical infrastructure (‘CNI’) assets;
- software supply chain risk management (‘SCRM’) by CNI operators; and
- critical software risk to CNI assets (my thesis).
With this in mind, the CrowdStrike incident-non-incident has the ‘Thesis Trifecta’ for me:
- a critical software vendor messing up; which jeopardises
- the cyber resilience of the operators of critical infrastructure (‘CNI’) assets; and thus captures
- the incredible risks to national security from software supply chains.
To nut out the Trifecta, I’ve written three pieces: one on each Limb.
Article 1 set the scene with Limb 1 — the anatomy of the stuff-up from a critical software vendor, CrowdStrike.
Article 2 dives into Limb 2 — how CNI asset operators were caught up in this saga.
Let’s begin, shall we?
A Lot Happened
Mr Cimpanu provided an excellent summary of how this incident-non-incident disrupted the cyber resilience of the operators of CNI assets around the world:
Planes were grounded across several countries, 911 emergency systems went down, hospitals canceled medical procedures, ATMs went offline, stock trading stopped, buses and trains were delayed, ships got stuck in ports, border and customs checks stopped, Windows-based online services went down (eg. ICANN), and there’s even an unconfirmed report that one nuclear facility was affected.
A number of CNI sectors represented right there.
To drive it home (albeit without Andy and Gazey), here’s how US airspace changed.
As part of the disruption of flights around the world, a number of travellers (including fellow Australians) were left stranded. The refund bills awaiting airlines, especially in the US, are eyewatering. Delta Air Lines says the incident-non-incident (‘the CrowdStrike disaster’ as the airline’s counsel calls it) bricked over 37,000 computers and affected over 1.3 million Delta customers.
UK general practitioners could not access patient EHRs because the relevant SaaS solution was down, forcing the NHS to revert to manual procedures. As if it (and the UK’s national blood supply) already wasn’t under enough stress from the ransomware attack against Synnovis.
(On the nuclear facility stuff, note that the: US Nuclear Regulatory Commission said, ‘U.S. commercial nuclear facilities reported that they are operating safely’; and US National Nuclear Security Administration said around the time of the event that the Department of Energy ‘is working with CrowdStrike, Microsoft, and federal, state, local, and critical infrastructure partners to fully assess and address system outage’, whatever that means.)
The following meme also made the rounds.

On top of pretty much everything running on Microsoft products (like Windows), we have CrowdStrike acting as one of the very few critical points of failure. An EDR vendor of choice for quite a few CNI people around the world.
The Office of the National Cyber Director called out this sort of risk in May:
Critical infrastructure owners and operators rely on third-party service providers to manage key aspects of their digital operations.
Now, while this incident-non-incident was not destructive like NotPetya (thank goodness), the disruption was certainly more widespread, given the estimate of 8.5 million Windows machines being affected. And even then, remediation advice was out within hours and CrowdStrike said over 97% of those boxes were back up and running within a week.
As Rob Graham put it, ‘This disruption was broad, but not deep’.
That said, as Rob highlights, these stats do not change the fact that CrowdStrike customers, including CNI operators, were bricked thanks to a catastrophic unforced error from their ‘trusted’ EDR vendor.
And it is because those CNI operator-customers’ Windows boxes were bricked by their vendor that this incident-non-incident is especially unforgivable.
Brian in Pittsburgh captured it quite well.
As the CISA Director explained in her write-up:
… our nation’s critical infrastructure … is, broadly speaking: highly digitized, highly interdependent, highly connected, and highly vulnerable.
And this reality is brought into unfortunately sharp relief whenever disruptions of the cyber resilience of CNI asset operators occur, malicious or otherwise. Especially so during the incident-non-incident.
If the stakes were already high because we’re talking about a critical software vendor messing up (Limb 1), they’re heightened thanks to the operators of CNI assets having to clean up that mess (Limb 2).
Just look at the definition of CNI itself under 42 USC § 5195c(e) (emphasis added):
… systems and assets, whether physical or virtual, so vital to the United States that the incapacity or destruction of such systems and assets would have a debilitating impact on security, national economic security, national public health or safety, or any combination of those matters.
‘Nuff said.
Sending in the Cavalry
To thankfully reiterate, the CrowdStrike incident-non-incident was not a NotPetya.
Nonetheless, given the scale of the (potential) disruption here — CrowdStrike’s customer book features CNI operators — governments mobilised their national crisis response mechanisms to coordinate what can be described as, collectively, the largest incident response exercise in history.
Our National Coordination Mechanism (a public-private crisis response coordination forum) convened four times and was briefed by CrowdStrike.
The Poms triggered COBR.
The Yanks quickly set up an interagency task force (can’t recall a Cyber Unified Coordination Group being set up for this one as it was for SolarWinds?). Deputy NSA for Cyber and Emerging Technology, Anne Neuberger’s, day started at 4 am ‘with a call from the [White House] Situation Room’.
Governments weren’t going to leave anything to chance when cleaning up after CrowdStrike with the private sector. And rightly so.
Which made clear how important this event was in signalling, especially to governments, the risks to CNI cyber resilience from the assets’ software supply chains.
And hey, the collection of national incident response work was a great sign in terms of public-private coordination mechanisms becoming more effective.
Yes, by necessity, given the realities of CNI being owned and operated largely by the private sector and thus requiring ‘a national cybersecurity posture rooted in public-private action, collaboration, and partnership’.
But still really good to see, especially compared to, say, ten years ago.
Messaging
Speaking of the role of government in that public-private partnership, may I point out that the messaging from governments, at least mine, has been a tad weird on this incident-non-incident?
It was presented by the then-Minister merely as a mistake made by the vendor which then ‘issued a fix’.
While those words were true, come on, this was a de facto ransomware attack from a ‘trusted vendor’, triggering national crisis response mechanisms for more than one meeting because of the disruptive effect on CNI assets. And the ‘Our technological dependencies are big sources of risk’ messaging was trotted out.
Which made these two later posts by the then-Minister contradictory.
On the one hand, ‘it will take time until all affected sectors are completely back online’. On the other, ‘There is no impact to critical infrastructure’.
The Prime Minister similarly said, ‘There is no impact to critical infrastructure’.
How so, especially when:
- payments processing was down;
- domestic airports’ operations were disrupted (with Jetstar cancelling all its flights in Australia and New Zealand);
- self-checkouts weren’t working at outlets of Coles and Woolworths (both designated by the Commonwealth as critical supermarket retailers); and
- the ABC and Sky News were unable to (normally) broadcast?
But then again, I understand that governments like mine didn’t want mass panic from something which was clearly non-malicious. They were rightly saying that this was on CrowdStrike (and not directly on the state — see more on that front in Limb 3).
Also, there are no votes in cyber resilience, so there was little point in governments making themselves the face of responding to a crisis from an unforced error by a company few civilians have even heard of.
(Separately, there has been some chatter about whether the Australian Security of Critical Infrastructure Act 2018 (Cth) (‘SOCI Act’) needs reform because of this incident-non-incident. I say, ‘Nah’.)
But Don’t Forget the Core Issue Here
We can talk about the state sending in the cavalry to coordinate national incident response all we like, but I return to the issue at the heart of this incident-non-incident:
The critical software vendor should not have messed up in the first place (as argued in Limb 1).
Folks, if you follow me on social media, you will see my regularly railing against the quality of software SCRM by CNI asset operators, my calling for better oversight of vendors and all that; especially with the number of SCRM regs out there, such as under the SOCI framework and CPSes 231 & 234 over here.
This is on top of the number of attacks against CNI assets via critical software products running on them (see Appendix), as well as the deteriorating threat environment for software supply chains, especially open source software (we all know about the luckily-averted xz utils debacle).
An idealist, I want CNI asset operators to be able to audit the living daylights out of their critical software vendors (that’s kinda my thesis). If they can’t perform that auditing/have it done by an independent third party, well, they might as well be trying to feel their way around in the dark with both hands tied behind their backs.
To reiterate Kevin Beaumont’s point, there is nowhere near the necessary level of transparency from cyber vendors like CrowdStrike about their code and procedures, and I’d safely assume that that can be extended to all software vendors. Kinda what the European Commission argued in its impact assessment accompanying the proposal for the Cyber Resilience Act (emphasis added):
While fewer vulnerabilities in products with digital elements and more transparency on the side of manufacturers as regards the security properties and secure use of products would not eliminate such costs altogether, more secure hardware and software and better documentation and instructions could lead to a notable reduction in costs.
This incident-non-incident is pretty much on CrowdStrike for failing to adequately test what it swings into customers’ kernels, and to allow customers to review the vendor’s update procedures and make patch management decisions accordingly.
A breach of trust all the more galling, given that EDR customers are on a hiding to nothing — the solution cannot be, ‘Do not have cyber resilience controls and do not install updates from your vendor’.
Solutions, People!
So, it’s clear that more vendor transparency is required.
But how are we to attain it?
Well, while we impatiently await governments mandating that transparency from all software vendors — at least to customers that operate CNI assets — through legislative reform, one piece of low-hanging fruit is for antitrust agencies to expressly authorise CNI asset operators to collectively bargain with their vendors to ensure that the latter meet minimum SDLC hygiene and other product security requirements.
Indeed, the NCSC CTO, Ollie Whitehouse, suggested this measure to leverage market forces.
Antitrust folk justifiably identify this incident-non-incident as reflective of dangerous concentrations that are allowed to build up and jeopardise national (economic) security (the subject of Limb 3).
Which is why antitrust folk must specifically say that said collective bargaining is okay to provide certainty to CNI asset operators’ lawyers as they try to make sense of their relationships with large(r) software vendors, especially critical software vendors.
As I said, it’s low-hanging fruit.
All the more so, considering the dearth of progress on this front, as Ollie pointed out:
… how we cohere the voice of what is the accepted minimum now in these systems, I think, we have yet to go.
CNI Asset Operators Can’t Fob Off Governance to Vendors
That all said, no one has clean hands here.
CNI people can’t outsource their own cyber governance to their critical software vendors, critical dependence notwithstanding.
As someone in industry pointed out to me, all software end-users, especially in CNI sectors, ought to create robust test environments. It’s cheaper to test updates from vendors relative to commissioning and/or performing vendor auditing, which costs a lot, takes a while, is fraught and is unlikely to lead to rapid change in vendor practices. On the other hand, customers can swiftly test an update and, if it’s a dud, they can ring up the vendor who can then (fingers crossed) de-dud the update, protecting customer production environments.
The Register has a great piece on the lessons that organisations need to learn regarding patch management, especially literacy in their vendors’ update policies.
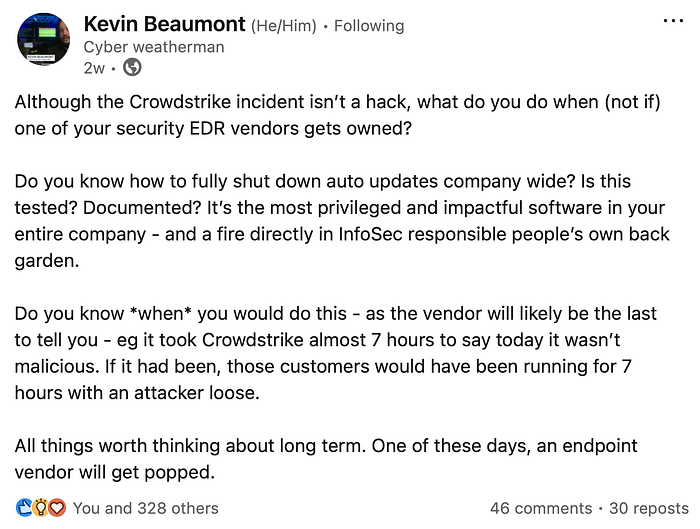
Kevin Beaumont also had some good questions for admins preparing for the next (inevitable) incident-non-incident.
The imperative for customers to wisen up at their ends are reinforced by Brian in Pittsburgh’s excellent thread on the realities of software SCRM for CNI asset operators. (I’ve popped two posts from the thread below.)
In terms of CNI people keeping their own noses clean, CrowdStrike has alleged (in a letter dated 4 August from counsel to Delta Air Lines’s legal team) that the airline resides in a glass mansion (Limb 1 went through the two companies’ battle of lawyers’ letters).
Even Microsoft has said in a letter (dated 6 August) from counsel, ‘Glass Mansion, mate’ (emphasis added):
… on Wednesday, July 24, Microsoft CEO Satya Nadella emailed Delta CEO Ed Bastian, who has never replied.
… to understand why other airlines were able to fully restore business operations so much faster than Delta ... Our preliminary review suggests that Delta, unlike its competitors, apparently has not modernized its IT infrastructure, either for the benefit of its customers or for its pilots and flight attendants.
In a letter dated 8 August, Delta’s counsel has replied tersely to CrowdStrike’s lawyers.
I’ve included this extract from the 8 August letter because it underlines why software SCRM is so important:
Contrary to your [CrowdStrike’s] misrepresentation of Delta’s technology, the reason for Delta’s disproportionate experience relative to other airlines, was its reliance on CrowdStrike and Microsoft. Approximately 60 percent of Delta’s mission-critical applications and their associated data — including Delta’s redundant backup systems — depend on the Microsoft Windows operating system and CrowdStrike.
Indeed, to return to the section heading, ‘CNI Asset Operators Can’t Fob Off Governance to Vendors’.
To continue interrogating cyber governance by OT operators (like airlines) with respect to critical software products, folks, what does the CrowdStrike Falcon Fiasco mean for the accelerating IT-OT convergence?
KISSing Is Wonderful
As part of driving home (albeit without Andy and Gazey) the importance of CNI asset operators taking charge of their own cyber resilience, the incident-non-incident reinforces the criticality for them to Keep It Simple, Stupid.
For starters, having comprehensive asset and credential (okay, at least BitLocker key) inventories.
Far easier to execute BCPs if you know what and where your endpoints (and BitLocker keys) are.
Linked with that, this saga has shown the criticality of doing realistic DFIR exercises, including with your material third party vendors, using these to develop robust BCPs and then rehearsing said BCPs regularly.
Indeed, this incident-non-incident showed what BCPs are meant for.
Considering how hard IT/cyber staff toiled and how most things were back up and running within a week or so, it could be argued that a lot of organisations did well in executing their playbooks.
To wit, Aon ran a poll during their webinar a week after the incident-non-incident: 83% of respondents said they had an IR plan, 76% said ‘it performed well’.
To state the obvious, however, there is a lot for CNI people to do in terms of the basics. The Australian Prudential Regulation Authority said just that in July 2023 when releasing an audit of the compliance by around a quarter of Australian prudentially-regulated institutions with sectoral cyber resilience regs.
The findings were far from encouraging, with the most common control gaps including (emphasis added):
incomplete identification and classification for critical and sensitive information assets;
limited assessment of third-party information security capability;
inadequate definition and execution of control testing programs;
incident response plans not regularly reviewed or tested;
limited internal audit review of information security controls …
Sheesh.
Conclusion
Alrighty, so we’ve done Limb 1— critical software vendor messing up.
And now we’ve dissected Limb 2 — the cyber resilience of CNI asset operators being jeopardised.
Onto Limb 3 — given Limbs 1–2, this incident-non-incident captures the national security risks from software supply chain risks.
Which shall be examined in Limb 3.
P.S. There were (alleged) silver linings from this incident-non-incident for CNI asset operators.
Appendix — Critical Software-Enabled Attacks against CNI Assets
Here’s a slide from my 2023 Cybercon preso.

In there, you’ve got:
- Stuxnet (likely 2005–2010) — Iranian defence industrial base (we know what those centrifuges were for): bugs in OT software;
- BlackEnergy (2015) — Ukrainian electricity utilities; lack of MFA on operators’ remote access software + using local SCADA deployment to open circuit breakers;
- WannaCry (2017) — UK and/or European healthcare, telecommunications and railway services; Windows bugs.
- AcidRain (2022) — satcom/Internet for the Ukrainian military and parts of Europe (eg French emergency services losing primary comms + remote monitoring and control for 5,800 wind turbines); misconfigured VPN.
Also note attacks like:
- Colonial Pipeline (2021) — US liquid fuel; VPN being sans MFA;
- allegedly, Medibank (2022) — Australian insurance; VPN being sans MFA;
- DP World (2023) — Australian stevedoring (with serious flow-on effects for Australian logistics); unpatched Citrix (#CitrixBleed); and
- Several MSPs (like Visma EssCom) and hundreds of Coop supermarkets in Sweden (2021) — data storage and processing, Swedish food and grocery; malicious Kaseya update.
The critical software products targeted in these examples reflect the growing cybercriminal preference, as identified in the ENISA Threat Landscape 2023, for remote monitoring and management tools in order to (easily) establish and maintain persistent access to victim environments.
After all, these are ‘trusted products from trusted vendors’, so customer environments would not be treating traffic coming through/from these boxes/their update channels as inherently suspicious.
#CriticalSoftwareMatters

